America's Secret Pager Giant

This article was originally published on HackerNoon.
Early January 2022, I spontaneously bought a pager. I looked into the US pager market, and to my surprise, there were (and still are!) several companies offering pager service. After a bit of digging, I decided to sign up for MySecretaryUSA’s two-way pager plan.
While waiting for a pager to be shipped, I started to do some digging. The “Paging Coverage Area Maps” and “Send a Page” links on MySecretaryUSA’s site took me to two websites: spok.com and usamobility.net respectively, which immediately told me that MySecretary is a Spok/USA Mobility reseller.
At the time of writing, I found competing resellers, but all of them were using Spok’s network. It stands to reason that the only company offering truly nationwide paging service, as opposed to local providers that serve a single city or state, is Spok (and Spok themselves claim to be the nation’s largest paging network). However, in order to understand Spok as a company, I first had to understand how pagers work.
Pager Recap

In short, a pager is a small battery-powered device that displays messages on the go. When they were first created, they could only play a specific tone, but as technology evolved, they could play voice messages, display phone numbers and text, and eventually reply to messages. Their use among the general public significantly diminished after the popularization of cell phones, and they currently enjoy widespread use in hospitals and other medical institutions, where mobile network coverage may be spotty.
The pager I have is a two-way pager, meaning it can send and receive messages. My plan includes 3000 messages a month, as well as SMS messaging, a voicemail box, nationwide access, and a whole host of other features. It is worth pointing out that a pager without a plan is mostly useless to the average person. Just like a mobile phone without a SIM card can’t use any cell network (except for emergency calls), a pager needs to be activated and assigned a capcode, or a unique ID in the paging network, in order for it to work. However, hobbyists have found ways to resurrect them. If you haven’t read Dmitrii Eliuseev’s article about several of those ways, I highly recommend it.
Most modern pager plans also come with a free phone number. That phone number is how you interact with the pager: you can call it to leave a voicemail, you can text it to send a page to it, etc. When I signed up for my plan, I was asked what area code I wanted the pager to have. Since my university has courtesy phones with free local calling, this allowed me to have a voicemail box freely accessible from any phone on campus.
Spok Recap
Now that we know how the pager ecosystem works, let’s talk about Spok. Spok came about not because of aggressive network expansion like most modern cell carriers, but because of legacy. Part of its legacy is the largest paging network in the country, with coverage in 44 states, but how it acquired that legacy is an interesting story.
“In 2014, two powerful communication companies, USA Mobility and Amcom Software, merged into one cohesive business — and Spok was born” — Spok Inc.
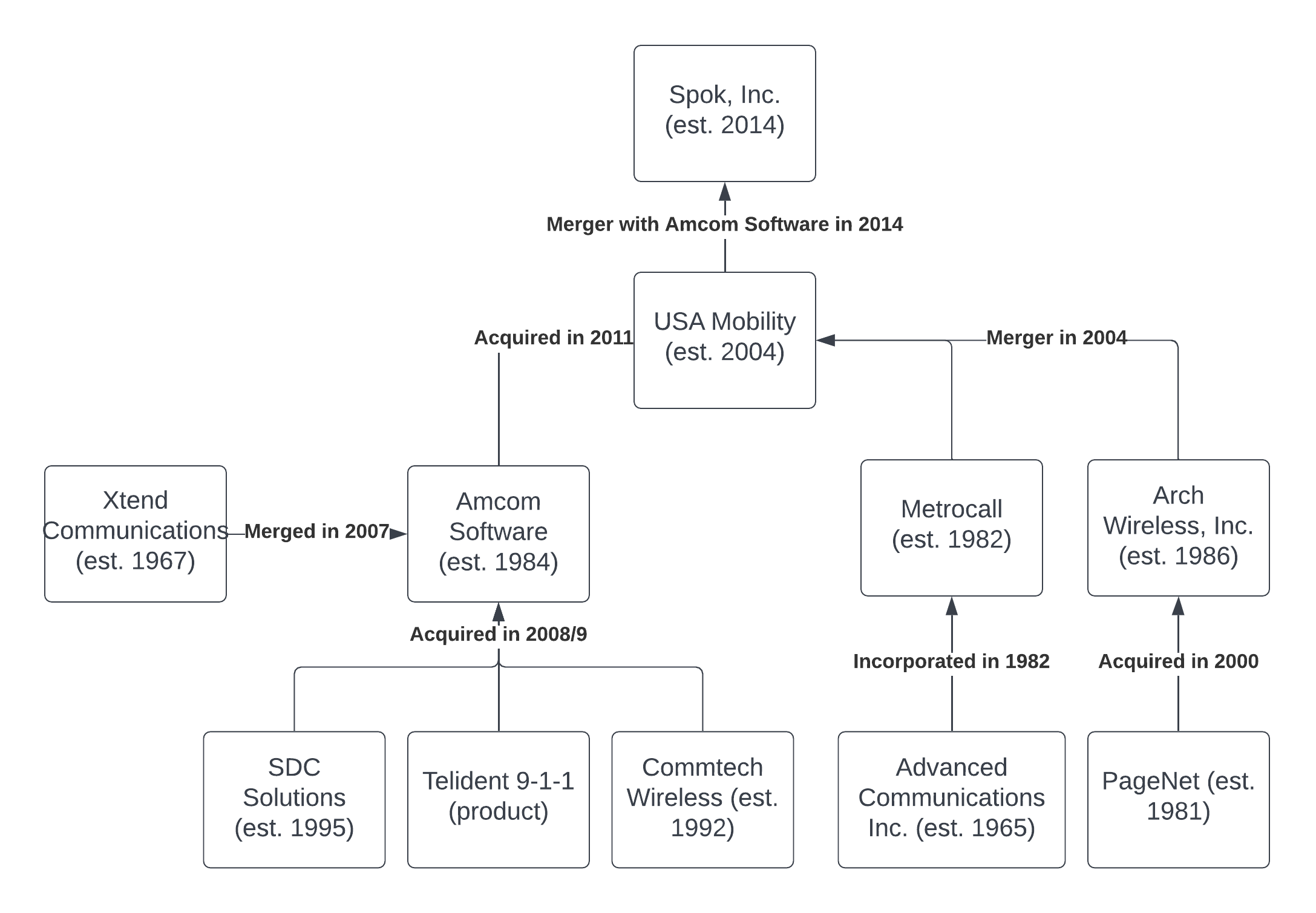
Spok’s history technically started in 1965, one year after Motorola released their first consumer tone-only pager, the Pageboy I. However, Spok itself is relatively young, coming into existence only in 2014 via the merger of two large industry players: USA Mobility (who handle the paging/wireless side of things) and Amcom Software (a communications software company). As you can see by the flowchart above, Spok is the result of almost half a century of mergers and acquisitions.
Nowadays, Spok is primarily a healthcare-oriented business. Most of the promotional language on their website and Twitter account is targeted to healthcare institutions. Consumers can no longer purchase paging coverage directly from Spok, instead having to go through resellers and other third parties.
You might be wondering why I called Spok a “secret paging giant”. That’s because most people outside of the healthcare industry haven’t heard of them, but they have most likely visited a practice employing their products at least once. According to Spok’s 2021 Full Year earnings call, every top 10 children’s hospital and top 20 adult hospital has some sort of relationship with Spok, with the oldest one being 42 years!
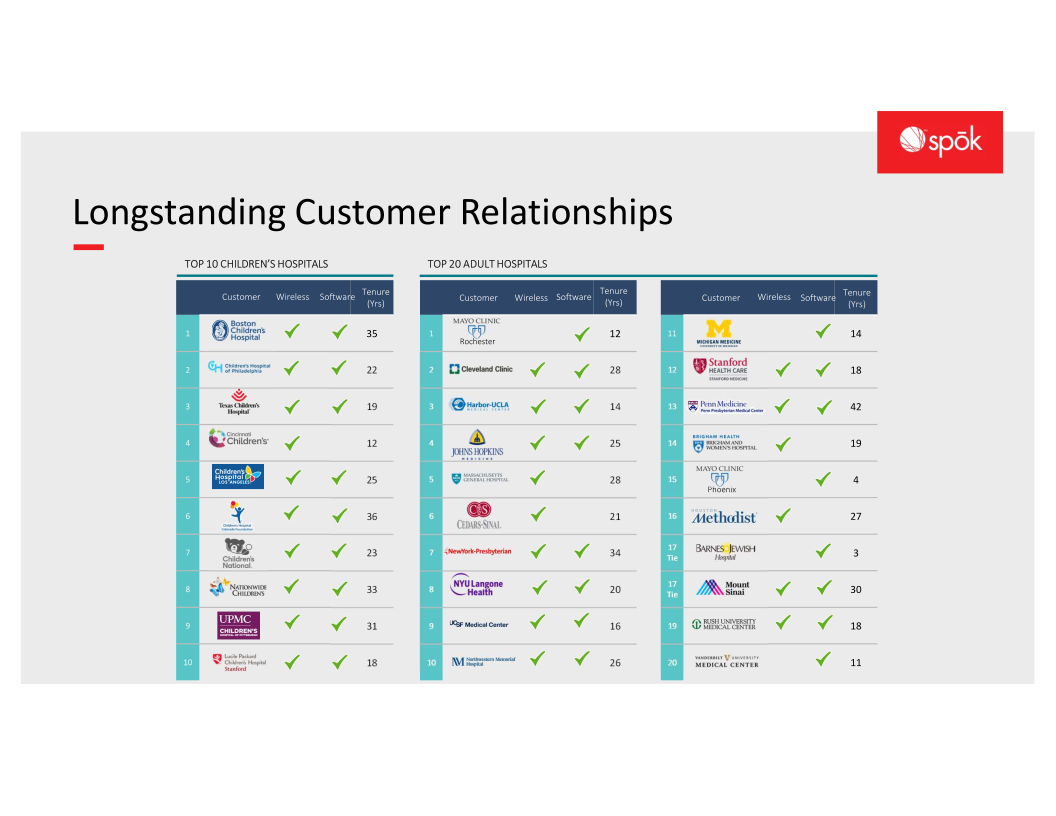
Many of these hospitals have been using Spok’s pagers, as well as their software, for several decades, and these “Longstanding Customer Relationships” very rarely break, especially in an field as technologically inflexible as healthcare. If something works well, there’s a chance it’ll remain maintained for decades, maybe even centuries. That is Spok’s legacy, and their bread and butter going forward.
CLICK HERE for Free Private Data
At this point, I had spent about a week on-and-off digging into Spok. The next logical question I had was “How many customers does this company have?” The answer is not publicly available. Spok published an infographic called “The ongoing power of paging,” where they mentioned that their network processes “more than 100 million messages/month”, but this number did not give me any clues to the total number of paging customers.
The solution to my problem came to me while I was looking at the “Send a Page” page. Amongst the various text boxes was the line: “Need to verify the number? CLICK HERE to validate device numbers”.
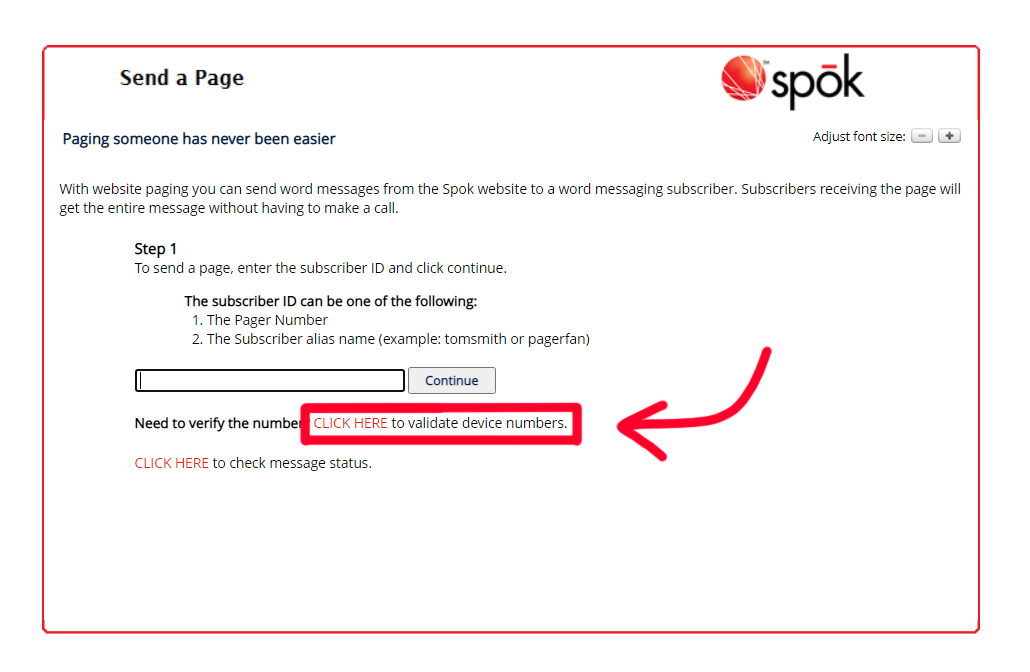
Upon pressing the button, you are asked to enter a number to validate, and the page makes a request to a CGI that tells you if the number is valid.

Great, now I had a way to check if a certain number belongs to Spok or not. At this point, all I needed to do is feed a every single possible number I could into that endpoint, and I’d not only get the total amount of customers Spok has, but I’d also get their numbers. Sounds simple, right?
However, I was now presented with a problem: the standard US phone number (xxx-xxx-xxxx) is 10 digits long. Going through all 10 billion possible combinations would take infeasibly long, so I needed a way to narrow down the scope of possible numbers. Thankfully, there is a way to do just that.
NANPA To The Rescue
NANPA is the North American Numbering Plan Administrator, the governing body responsible for administering and allocating area codes and central office codes within the North American Numbering Plan. They also publish regular reports about their activity, one of which caught my eye, the “Central Office Code Assignment Records” report.
The report page contains a wealth of information, but the file that concerns us is “allutlzd.txt”, a text file that lists all the assigned central office codes in the United States. These are digits 4–6 of a phone number (xxx-xxx-xxxx). Searching for “SPOK, INC” in the text file yields 0 results, but knowing their their former business name, I searched for “USA MOBILITY WIRELESS, INC” and, bingo!, I got 2336 matches.
Here’s a typical line from the text file:
WI **262–231** 6630 “USA MOBILITY WIRELESS, INC.” LAKEGENEVA AS N.We don’t need to worry about anything except the second column, which gives us the area and central office code assigned to Spok. 2336 matches times 10000 numbers in a central office code is 23.36 million unique numbers that could potentially be active. This narrowed my range significantly, but I could not possibly go through all of these numbers sequentially.

According to Insomnia, a single request to Spok’s checking CGI takes 80.5ms from start to finish, so if one were to run all the possible numbers through Spok’s checker, it would take 1.88 billion milliseconds, or around 21.8 days to complete all of the requests. Even for a one-time operation, this wait time is unacceptable. I needed to find a way to run many, many requests at the same time.
AsyncIO, meet HTTPX.
The first obvious step is to run these requests concurrently. Python has multiple ways to do this: multiprocessing, multithreading, and asyncio. I won’t go over the difference between these libraries, because that is out of the scope of this article, but I decided to choose asyncio. If you’re wondering what library to choose for your project, here’s an excellent Stack Overflow answer that might help.
Before I talk about how I automated the request process, I have to express my gratitude to Blair “r000t” Strater, who wrote the base code to quickly go through a single number range. Without his expertise, this project would have not been possible. He also suggested to use HTTPX and its HTTP connection pooling feature, which I will now briefly explain.
Every Python developer, no matter how experienced, has interacted with requests, probably the most legendary third-party library for the language. HTTPX is the spiritual successor to requests. Not only does it support HTTP connection pooling, but it has built-in Async support.
HTTP connection pooling works by establishing a single TCP connection to a server and reusing it for every subsequent request. Since establishing a single TCP connection every time one wants to make a request adds a lot of unnecessary overhead, especially when we’re making large quantities of requests every second, HTTP pooling helps us to reduce latency, CPU usage and network congestion without any additional costs.
With r000t’s help, I now had a working scraper that could submit hundreds of numbers a second to Spok’s CGI. Over the course of a few days (more on why this is significant much later in the article), I ran my script and gathered exactly 478,729 numbers. This amounts to a utilization of their NANPA assignments of about 2.05%. That’s a lot of room for future expansion!
Gathering Data
Now that I had all these numbers, it should be easy to correlate them to their respective ZIP codes, since central office codes are assigned to a geographical region, right
Wrong again. I had naively assumed that NANPA would provide that data publicly. Let’s look at NANPA’s website guide, where they claim:
“Here are some things you will NOT find on this site: […] Location of an area code/prefix. Applicants for prefix assignments are not required to disclose to NANPA the “localities” that the prefix assignments will serve. Thus NANPA does not have this information.”
The only location datum that NANPA does provide is “rate center”, which is only tangentially related to geography, and can be incredibly confusing to correlate to a real location. For example, look at the line:
CA 213–350 6630 “USA MOBILITY WIRELESS, INC.” **LSAN DA 01** AS N\nWhat does “LSAN DA 01” even mean? It’s related to Los Angeles somehow, but doesn’t give us any clues in regards to its zip code. However, in that same guide, NANPA says:
“information on the correspondence between zip codes and area codes is available through various sources on the web. Find them by using a search engine.”
And after exactly one Google query, I stumbled upon area-codes.com, whose easily-abusable website allowed me to correlate each central office code to a ZIP code. Two hours of automated Selenium queries later, I had a text file with all of the ZIP codes used by Spok. I combined all of them, counted all of the numbers in that zip code, and via Simplemaps’ US Zips Database, I now had all the states, cities, and counties Spok had customers in.
Except, It’s Never Really That Simple…
Firstly, I have to mention that just because these numbers belong to Spok, it doesn’t mean that they are “consumer” paging customers. One of Spok’s products is a turn-key contact center, and their main line of business is enterprise-level healthcare paging, which means a number could be a hospital’s main customer service line, or a doctor’s phone number.
Secondly, there is a degree of fallibility in my results. I am using ZIP codes as a proxy for location. Not only can area-codes.com’s database be inaccurate, but so can Simplemaps’. I am converting from central office code to ZIP, and then again to city/county/state. Any error at any step could give false results.
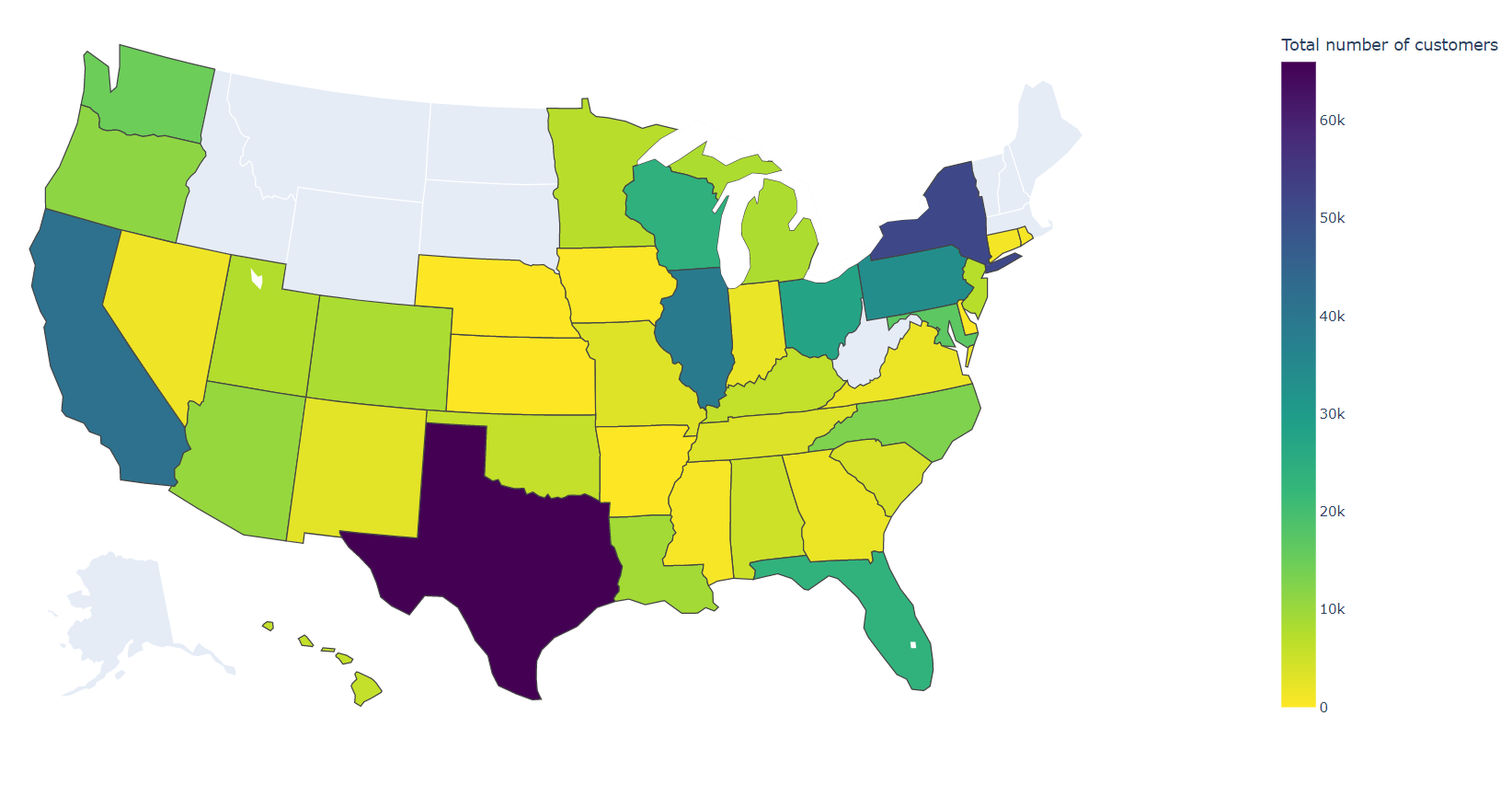
Let’s take a look at the State, County, and City graphs for the data I gathered:
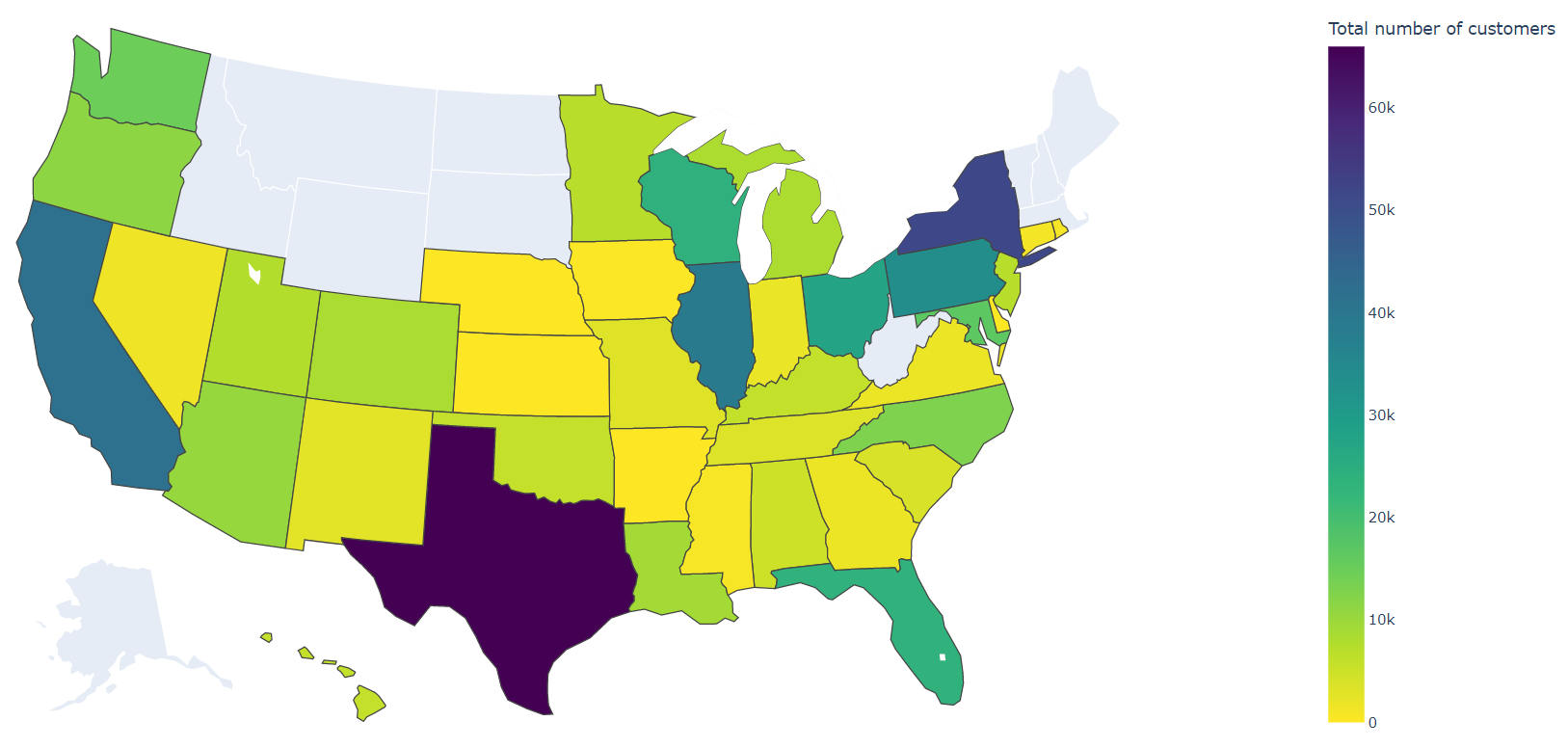
Total numbers of customers by US state. Visualization by Plotly
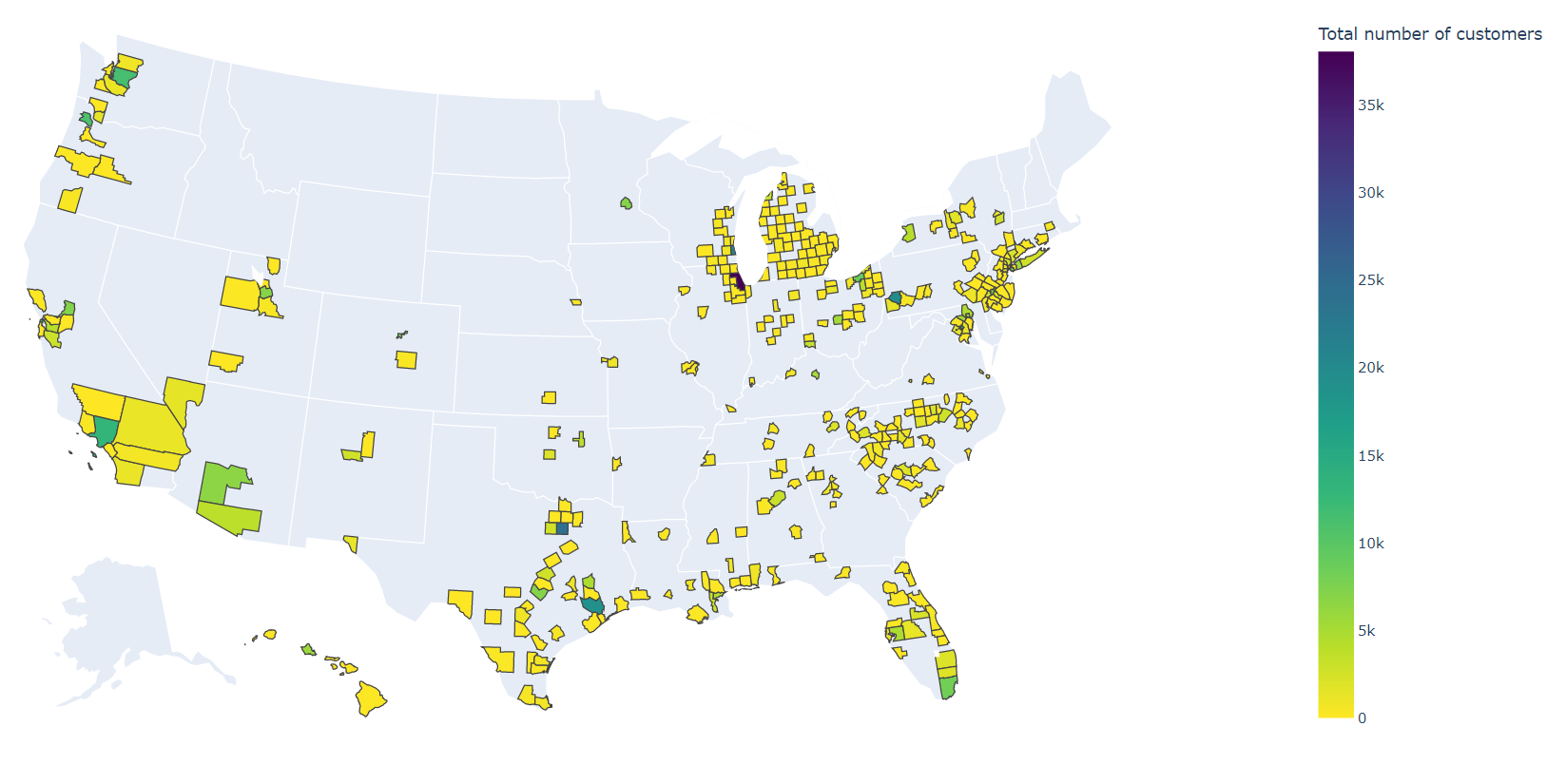

Three things jumped out at me immediately after I finished compiling these data:
- 479 thousand numbers isn’t all that much. Even if we assume all of these are paging customers, and do not contain any call center or service numbers (modems for the paging network, etc.), that’s, for example, 7.3 times less than the number of Facebook Messenger users in Costa Rica (according to Statista)
- The data are extraordinarily geographically spread, and customer counts rapidly drop off after the top 100 cities. The top 10 cities only make up 37.4% of all customers, but the top 100 cities make up 90.1% of all customers (out of a total of 501)
- I’m not particularly knowledgeable in US geography, since I’m an international student here, but I’ve never heard of Grand Prairie, TX before in my life. Why does that one city have so many pager numbers?
The Grand Prairie Anomaly
Let’s explore the Grand Prairie anomaly. The first thing I did was Google what “Grand Prairie” even is. Turns out it’s a city in the Fort Worth-Dallas twin city area with a population of about 194 thousand people (according to the 2020 US Census).
The second thing I did was go back to my raw data and sum up all the numbers with the “GRANDPRARI” rate center, since I assumed that numbers in that area won’t be assigned to any other rate center. To my surprise, I ended up with more numbers than in my city graph! 23973 as opposed to 23617 ZIP-geocoded numbers. This immediately tells us two things: either pagers have a 12.4% penetration in such a small city, or there’s another factor at play.
A clue could be hiding on Spok’s “Contact us” page. They claim to have two locations in the US: one in Alexandria, VA, another in Plano, TX. Looking at FCC filings (file number SESRWL2017071400761), they seem to have a ground satellite station at their address at 3000 Technology Drive, as seen on Google Maps satellite view.

Imagery ©2022 Maxar Technologies, Map data ©2022 Google
Plano is located in the Fort Worth-Dallas area just like Grand Prairie, but this alone doesn’t explain why so many numbers are located in that area. This could be anything from a cost saving measure (Grand Prairie is its own distinct rate center) to an amassing of corporate numbers for testing. I wish I had a more satisfying answer for this anomaly, but unless Spok clarifies the situation, we’ll never truly know.
Yet More Anomalies
The more I kept looking at the data, the more I was amazed by the uniqueness of this dataset:
- Grand Prairie, TX, number 135 (!) city in the US by population, is number 2 (!!) on my list
- Los Angeles, CA, number 2 by population, is on spot 23 (!!!)
- Milwaukee, WI, number 30 by population, is on spot 4
- Pittsburgh, PA, number 68 by population, is on spot 5
- Phoenix, AZ, number 5 by population, is on spot 19
(population data taken from World Population Review)
Even the cities with the most numbers occupy only a fraction of the total percentage of numbers. Chicago, IL, number one on my list, takes up only 5.79% of the dataset. Out of 501 cities:
Only the top 10 have more than 10,000 numbers
Only the top 83 have more than 1,000 numbers
Only the top 238 have more than 100 numbers
Only the top 359 have more than 10 numbers
There are 38 cities with only 1 number
And a single city with 0 numbers: Woodbury Heights, NJ
My favorite anomaly probably has to be Arkansas. Arkansas doesn’t have any pager towers, the only service that it gets is bleed-over from Memphis across state lines (see if you can spot it on the following map without my red highlight).
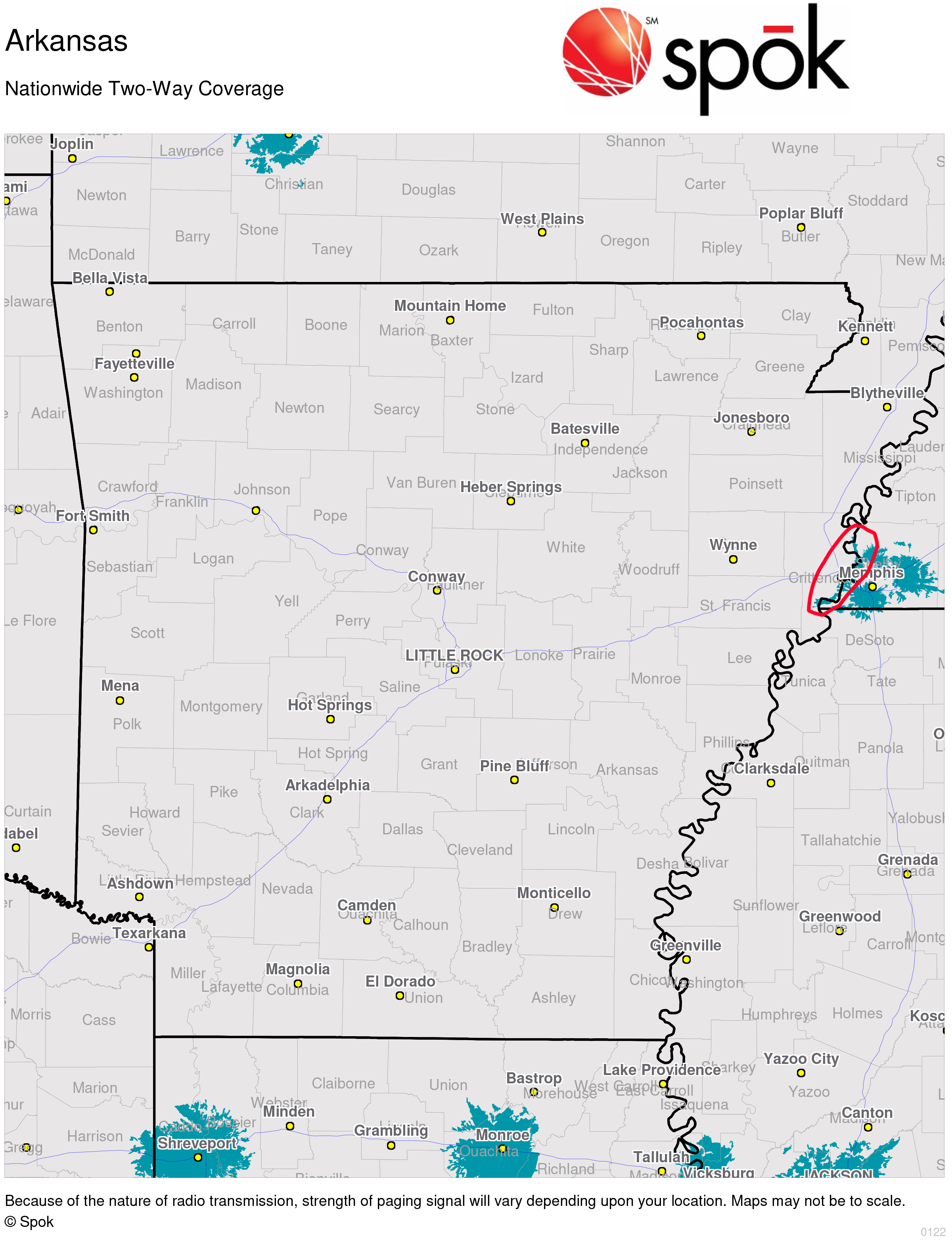
Despite this, in my dataset is a single number from Fort Smith, AR, a town with a population of about 87 thousand (according to the 2020 US Census), on the complete opposite side of the state border. Not only that, but it is the only Arkansas number in my dataset. I don’t think I can put into words the astonishment I felt when I discovered this.
This, however, is the perfect time for me to reiterate that a number doesn’t necessarily mean a pager is active in that area. The most likely explanation I have is that a customer from the Memphis area frequently called into Fort Smith or was stationed there, so it would be more convenient for them to acquire a Fort Smith number.
Conclusion
Spok is a fascinating company. They have managed to survive the death of consumer paging by clinging onto healthcare institutions, and yet they still offer paging service all across the country. Their legacy shows us how ancient tech can stick around long after it has been discontinued by manufacturers.
A careful reader might have started wondering how I was able to gather so much data from Spok in such a short amount of time. The answer is simple: the CGI I used didn’t employ any authentication, has no rate limits, and doesn’t employ any header checking. That CGI is a relic of an older, naiver time, when privacy was simply not thought of when it came to user interfaces. I was easily able to send 100 requests a second to it, and it only started to “choke” at around 250.
Nowadays, no such API (we don’t even use CGI’s anymore) would make it into production. Spok’s “Send a Page” website is a time capsule that shows us the pitfalls of legacy tech. Sure, you get to keep all of your old customers, but if you don’t maintain or proactively work to secure your old interfaces, some script kiddie (or, even worse, a competitor) might just show up and scrape all of your data.
I am choosing to open source the processed dataset for future researchers to play with (the raw numbers, however, will not be published due to ethical and privacy reasons):
https://github.com/evilsaloon/spok-dataset. I hope it is of some use.